






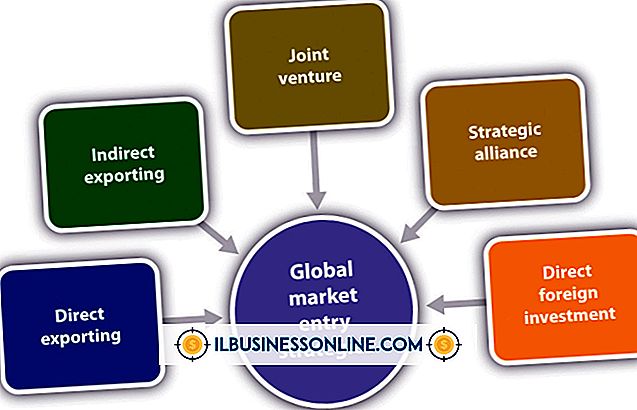

Een effectief spider-blok voor WordPress

Als er geen spiders waren, zouden we niet in Google kunnen zoeken naar webinhoud. Spiders zijn robots die het web doorzoeken en alles wat ze vinden indexeren zodat wanneer u naar artikelen over WordPress wilt zoeken, het weet waar die artikelen zijn en u naar hen kan verwijzen. U hoeft echter geen spiderindex WordPress te laten indexeren en er is een eenvoudige manier om een effectief spiderblok voor WordPress te maken dat spinnen van gerenommeerde bedrijven blokkeert. Een zelfs effectiever spiderblok bevat een aantal instellingen en een proces om slechte spiders te identificeren en te blokkeren die uw instructies negeren en Web-inhoud indexeren die u hebt aangegeven als verboden terrein voor spiders.
robots.txt
Wanneer een spider uw WordPress-site bezoekt, is het eerste wat het moet doen het "robots.txt" -bestand lezen. Dit bestand bevat regels die de bestanden en mappen specificeren die al dan niet kunnen worden geïndexeerd door alle spiders of afzonderlijk genoemde spiders. Een spin vindt zijn unieke "user-agent" -code in het bestand of een wildcard die "alle spinnen" aangeeft. Vervolgens wordt de lijst met bestanden en mappen gelezen die zijn toegestaan of niet toegestaan. Vervolgens begint het alleen de delen van de site te indexeren die mogen worden geïndexeerd.
Spiders blokkeren
U kunt een effectief spider-blok maken voor WordPress door een "robots.txt" -bestand in uw WordPress-hoofddirectory te maken en een regel op te geven die indexering van de hoofdmap van de site niet toestaat. Hierdoor is indexering van een submap van de root niet toegestaan. In het bestand moet u ook opgeven dat deze regel van toepassing is op alle spider-user-agentcodes. Elke spider die uw site bezoekt, moet het bestand lezen en weggaan zonder een deel van uw site te indexeren. Het "robots.txt" -bestand zou er bijvoorbeeld als volgt uit moeten zien:
User-agent: * Disallow: /
Goede en slechte spinnen
Er zijn goede spinnen en er zijn slechte spinnen. Goede spiders zijn van gerenommeerde bedrijven zoals Google, Yahoo of Microsoft en houden zich aan de regels in uw "robots.txt" -bestand. Slechte spiders zijn van individuen of bedrijven die opzettelijk het "robots.txt" -bestand negeren en mogelijk de volledige inhoud van uw site indexeren, ongeacht wat u toestaat of niet toestaat. Deze robots zijn soms op zoek naar specifieke informatie, zoals e-mailadressen, om te verkopen aan spammers, of persoonlijke informatie over gebruikers, om te verkopen aan andere bedrijven. De spiders doorzoeken uw hele site, op zoek naar informatie of inhoud die u niet goed hebt verborgen of beschermd. Verschillende webmasters hebben verschillende manieren om met malafide spiders om te gaan. Sommigen proberen eenvoudigweg te identificeren wie ze zijn en blokkeren het indexeren van inhoud op de site. Anderen proberen schade aan te richten door de database van de spider te vergiftigen met valse informatie of door de spin in een eindeloze lus te laten trillen die hem ofwel doet stoppen ofwel afbreken.
Honingpot
Een honeypot of tarpit is een techniek die door sommige webmasters wordt gebruikt om schurkenstaten te identificeren, zodat ze kunnen worden geblokkeerd. U kunt een honeypot maken door simpelweg een map toe te voegen die valse inhoud bevat, zoals e-mailadressen, en specifiek die map in het bestand "robots.txt" te weigeren. In de serverlogboeken wordt aangegeven welke spiders de directory hebben geopend en kunt u hun user-agent-tekenreeks en IP-adres registreren. Met die informatie kun je regels maken in het "htaccess" -bestand van WordPress die de toegang tot deze ondeugende spinnen ontzegt. De honeypot moet regelmatig worden gecontroleerd om te voorkomen dat nieuwe bedrieglijke robots toegang krijgen tot uw site.
Populaire Berichten

Reclameslogans zijn altijd een marketingstapel geweest voor grote en kleine bedrijven. De meest herkenbare merken hebben gedenkwaardige, pakkende sloganes die resoneren met consumenten, terwijl ze ook in de loop van de jaren verschuiven. Als het gaat om hun evolutie, zijn reclameslogans van traditioneel naar hedendaags gegaan, waarbij enkele van de grootste merken ter wereld het tempo hebben bepaald
Lees Verder

Je hebt hard gewerkt om het best mogelijke talent aan te trekken. Je hebt mensen ontwikkeld op het juiste moment, hebt geprobeerd het goede voorbeeld te geven en hebt ijverig gewerkt aan een positieve bedrijfscultuur. U hebt dit allemaal gedaan, omdat u weet dat het toevoegen van de energie aan uw team positieve bedrijfsresultaten oplevert
Lees Verder

De technische computeromgeving van MATLAB is geoptimaliseerd voor bewerkingen op matrices. Vaak heb je in MATLAB te maken met spreadsheet- of afbeeldingsgegevens waarbij het nodig is om een rij uit een array te extraheren om deze onafhankelijk te analyseren of weer te geven. Array-indexering van numerieke en celmatrices in MATLAB maakt dit proces eenvoudig. 1.
Lees Verder

Wanneer u een bedrijf runt met werknemers op uurbasis die overuren maken, kunt u het uurtarief van de werknemers berekenen evenals het percentage overuren. Om dit te doen, moet u het totaalbedrag kennen dat aan de werknemer is betaald, de reguliere gewerkte uren en de overuren die u hebt gewerkt. Gebruik bij het berekenen van het uurtarief de brutoloon voor de werknemer in plaats van na belasting
Lees Verder
Een aandeelhouder van een S-onderneming loopt geschorste verliezen op wanneer zijn toewijzing van verliezen voor de verslagperiode zijn netto-investeringen in het bedrijf overschrijdt. Verliezen die het belastbare inkomen van de persoon in de S-onderneming overschrijden, worden opgeschort en afgetrokken van toekomstige inkomsten
Lees Verder